



When we talk about Artificial Intelligence, we always consider mentioning Machine Learning. ML, as most tech developers call it, is a branch of AI that focuses on using algorithms and data to ensure that the machine starts imitating a human. With the help of machine learning, tech developers also enable machines to improve their accuracy.
When working towards Machine Learning, the most important aspects that everyone comes across are the decision tree and the Sklearn decision tree. Before we discuss Scikit-Learn or Sklearn Decision Tree in detail, let us explore the importance of creating a decision tree in machine learning:
- Decision Trees provide a transparent model that any expert and non-experts can understand.
- It is the inherent nature of decision trees to perform feature selection during the learning process, which allows for a natural identification of the most relevant variables.
- Decision trees are often used to capture nonlinear relationships within the data.
In this detailed guide, we will discuss the importance of the Scikit-Learn Decision Tree and how you can make one using the free templates provided by EdrawMind.
In this article
What is a Decision Tree
As the name suggests, a decision tree is a hierarchical model that tech experts often use to make important decisions. A detailed decision tree consists of nodes representing decisions, subsequent branches representing possible outcomes, and leaves representing the final decision that was selected based on multiple brainstorming sessions.
In order to understand how a decision tree makes informed decisions, we need to first categorize it into two segments -- Splitting Nodes and Leaf Nodes.
1. Splitting Nodes
Like most hierarchical models, decision trees start at the root node and make decisions by repetitively splitting data into different smaller subsets. This splitting is performed based on the feature values that these subsets hold.
Once the subsets are created, we then move on to the internal nodes. These internal nodes test specific (pre-assigned) features, and then the branches represent the possible values that these features can take.
2. Leaf Nodes
The recursive process continues to happen until a stopping criterion is met. These criteria can be anything from finding the solution to a problem to reaching a certain number of data points in a leaf.
As aforementioned, the leaf nodes contain the final decision based on the majority class of the data points in that particular leaf.
As you can see, the decision tree is an important tool when it comes to reaching a finite decision and has several advantages.
3. Advantages of Decision Tree
- It provides a transparent and easy-to-understand structure that represents the overall decision-making process.
- Most developers use it in those situations where interpretability is very important.
- Decision trees can easily model complex and nonlinear relationships into meaningful data.
That being said, decision trees have a few disadvantages as well.
4. Limitations of Decision Trees
- There are occurrences where one can find how decision trees are prone to overfitting.
- Small changes in the data can provide you with a completely different tree structure, and such instability is highly sensitive to variations in the training model.
What is Scikit-Learn
Scikit-Learn is a widely used machine learning library that offers a range of algorithms and tools that contribute to the overall success of machine learning in the Python programming language. Scikit-Learn is an open-source library that provides important tools for data analysis and modeling. Most Python developers use Scikit-Learn because of how effectively it provides machine learning algorithms and data preprocessing models.
The Scikit-Learn Python library is built on NumPy, SciPy, and Matplotlib, and it enhances the capabilities for visualization and heavy computing.
In order to understand Scikit-Learn in detail, let us first check a few of its most popular algorithms.
Popular Algorithms in Scikit-Learn
1. Supervised Learning:
It includes Linear Models, like logistic and linear regression, and Ensemble Methods, like Random Forests, AdaBoost, Gradient Boosting, and Nearest Neighbors for classification and regression tasks.
2. Unsupervised Learning:
Some of the Unsupervised Learning Algorithms that fall under Scikit-Learn are Clustering, which includes K-Means, DBSCAN, and hierarchical clustering for grouping similar data points and Dimensionality Reduction, where we use Principal Component Analysis, or PCA, for reducing the number of features while ensuring the original data variances are preserved.
3. Model Selection & Evaluation:
Here, we have two types of algorithms -- Cross-Validation, which provides tools for assessing model performance through k-fold cross-validation, and Hyperparameter Tuning, which helps in optimizing models through Grid and Randomized Search.
When it comes to machine learning, the advanced Scikit-Learn library is considered to be very important. Some of the benefits of using it are:
- It provides a user-friendly interface that helps beginners to get started with complex algorithms.
- Scikit-Learn's online community is very active, so one can easily get support and resources for their work.
- It easily integrates with other Python libraries, like Pandas, for data manipulation.
- It is also fully compatible with popular frameworks like PyTorch and TensorFlow.
How to Make Sklearn Decision Tree
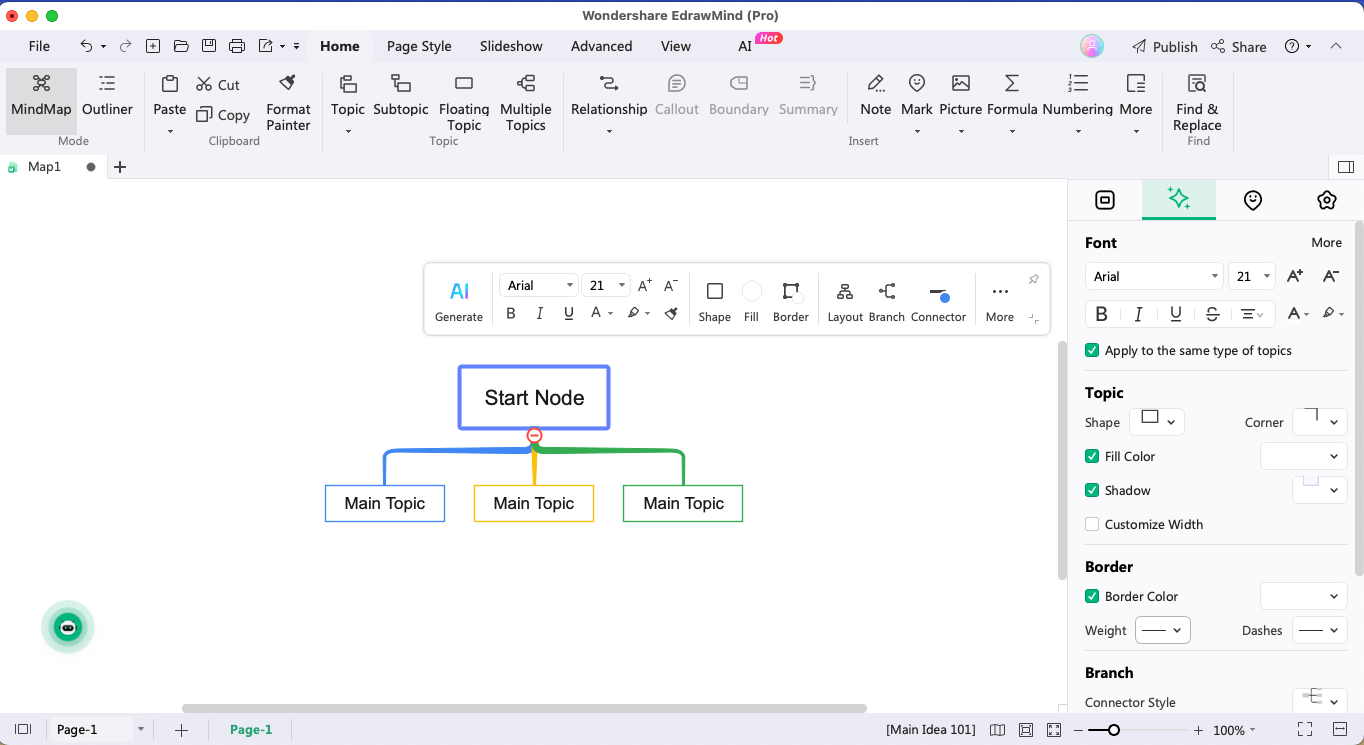
Step 1:Start Node
Start making the Sklearn Decision Tree by adding a 'Start' node. If you are using a tool like EdrawMind, then you can head to the homepage > New > Mind Map and start renaming the Main Topic with the 'Start' node.
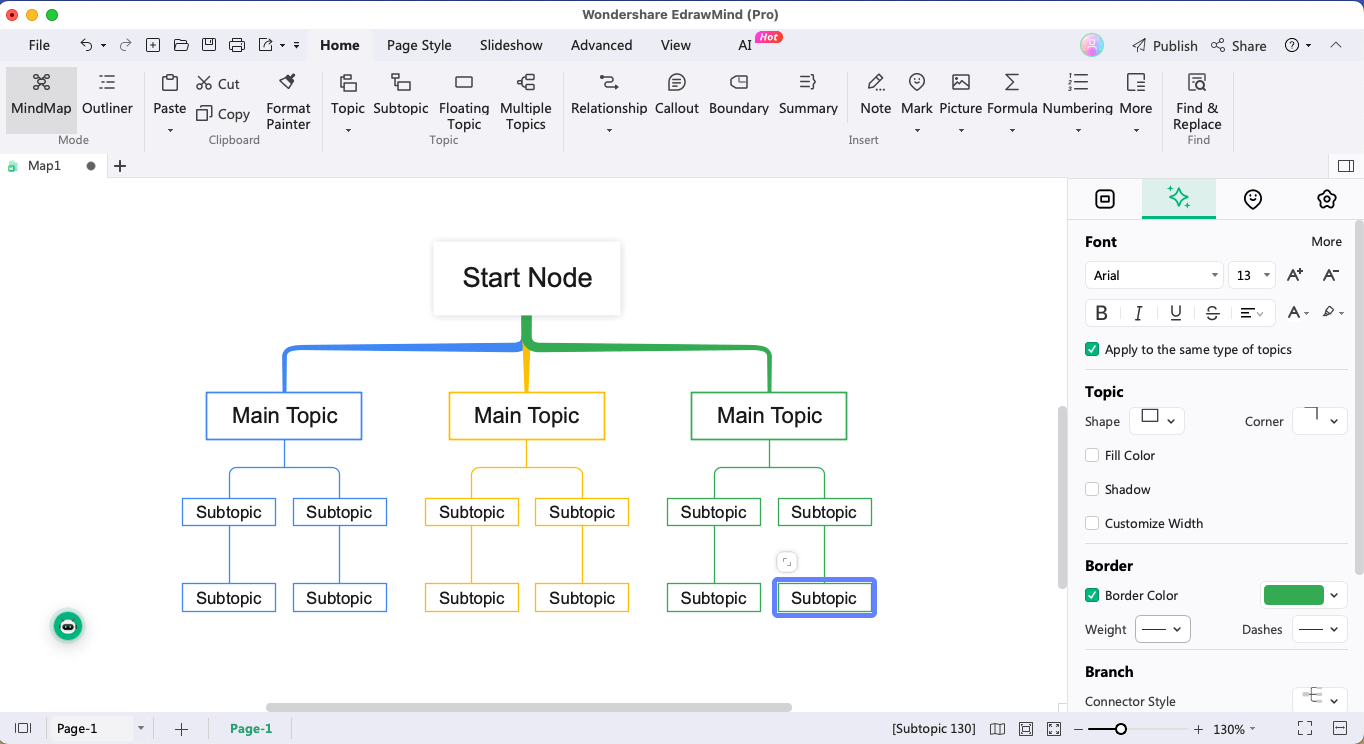
Step 2:Data Preparation
Now, add a process node that would represent how we are preparing the dataset. You can connect it to the 'Start' node. The data preparation stage also includes a process for data preparation tasks, like encoding categorical variables and splitting the data into target variables.
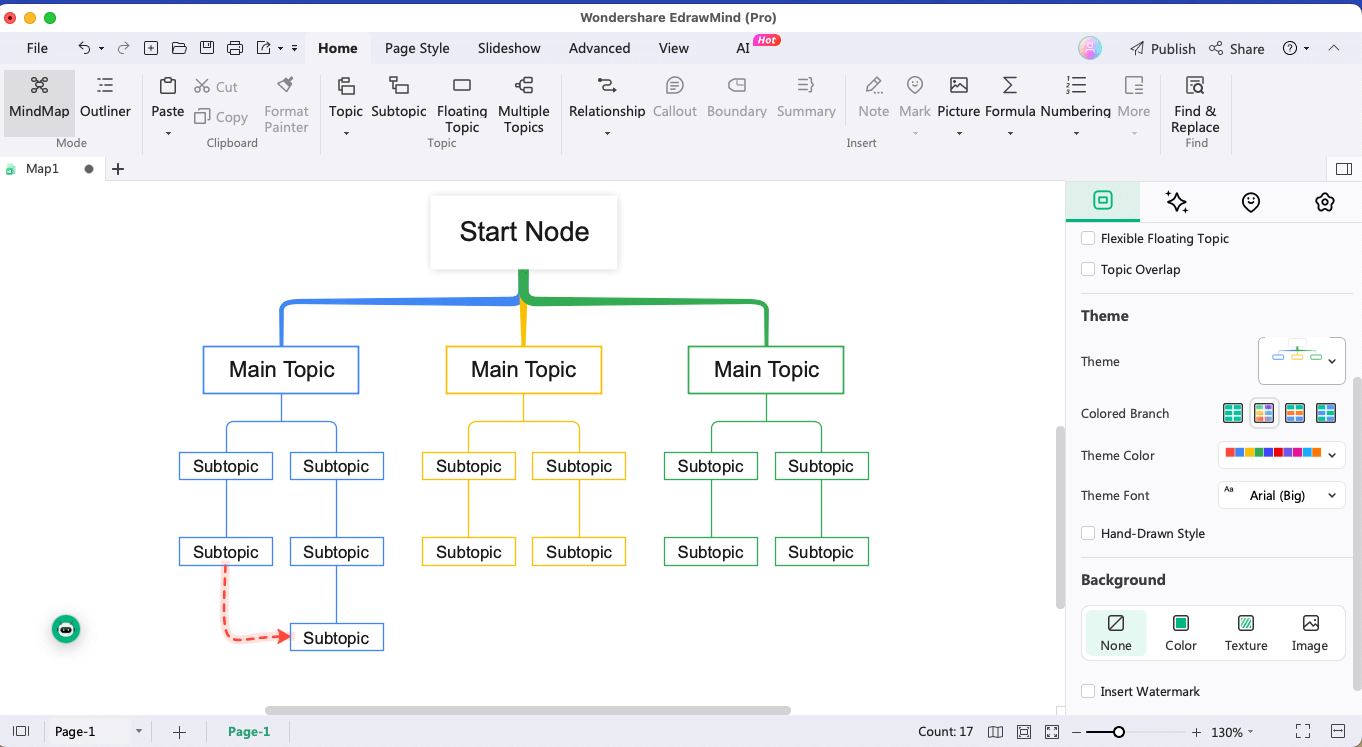
Step 3:Node Connectors
Add another process node that would represent how we are splitting the data into testing and training sets. Use EdrawMind's built-in connectors to connect this node with the data preparation step.
Step 4:Create a Decision Tree Model
From this decision tree model, add two branches -- Yes (if you plan to create the model) and No (if you decide otherwise). While training the model, include a process node for training the decision tree model and connect it to the Yes branch of the decision model. If you are making predictions using the trained decision model, connect it to the No branch.
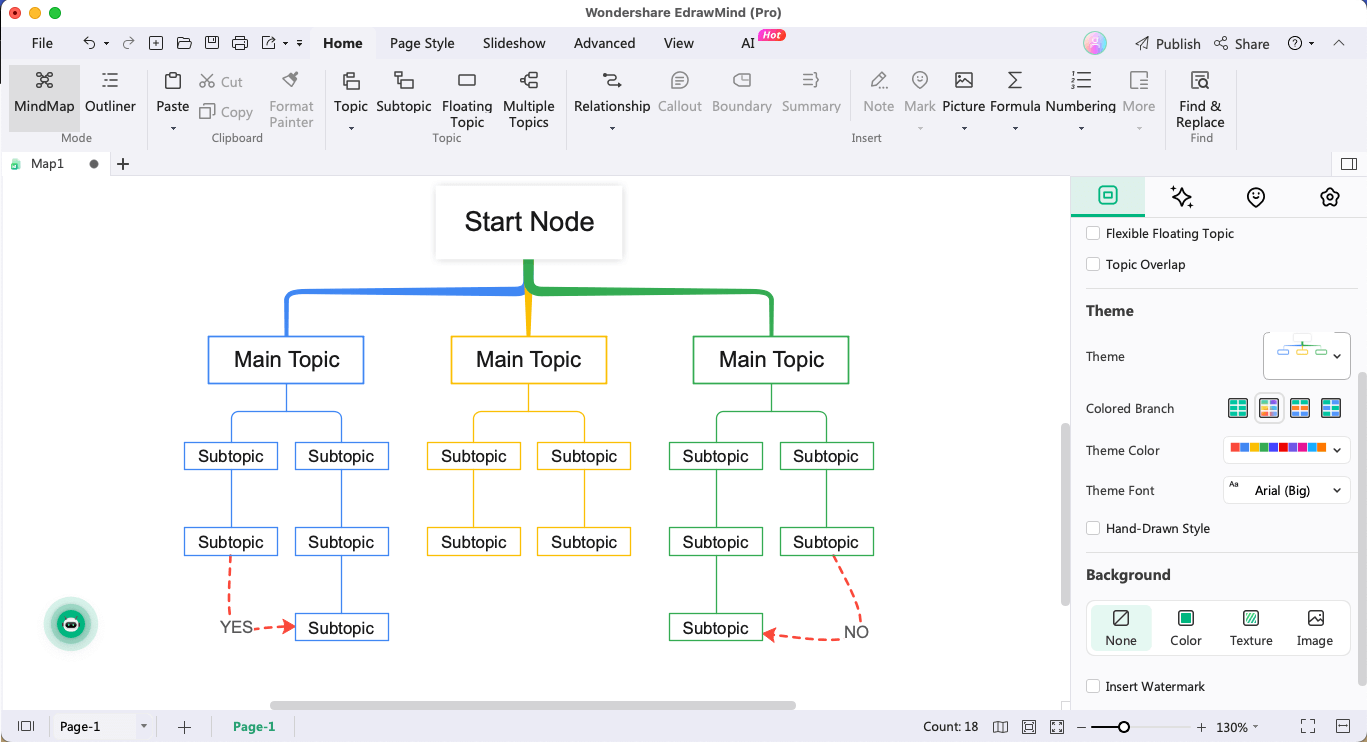
Step 5:Evaluate & End
You can evaluate the process node by performing different metrics, like accuracy and recall. In the end, conclude the flowchart by adding the 'End' node that would indicate the end of the overall process.

Sklearn Decision Tree Templates
In order to understand more about the Sklearn decision tree, we have outlined two templates for you.
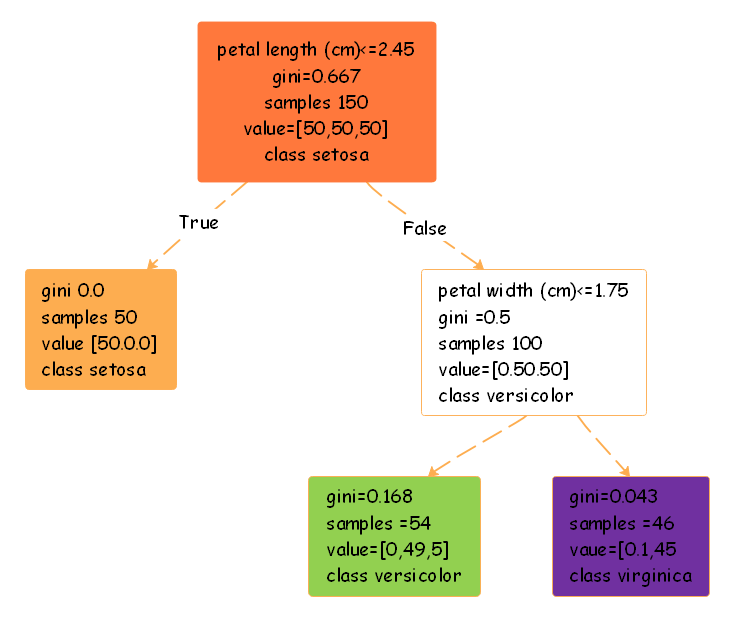
In the first Sklearn Decision Tree template, the decision-making process is based on the feature petal length and a Gini value. The nodes presented in this template have the initial database with 150 samples that are evenly distributed among three classes. If the condition regarding the petal length is true, it would indicate a threshold and the resulting subset has a Gini impurity of 0.0. If the condition is false, the decision tree would further consider the feather petal width and classify the instances into two subsets.
 below.
below.  below.
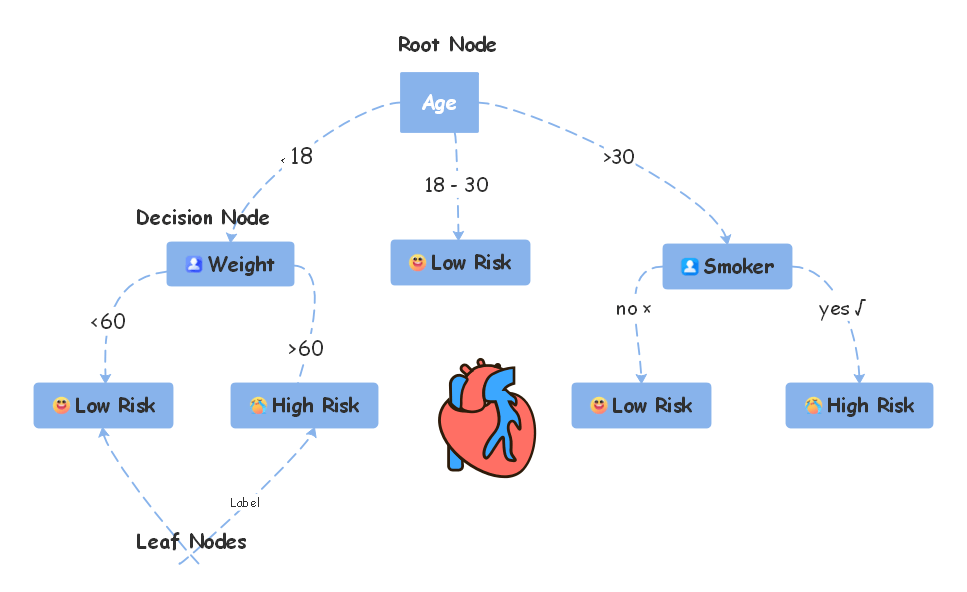
below. In the second Sklearn Decision Tree template, we are addressing the possibility of having a heart attack. The Root Node in this Sklearn Decision Tree revolves around the individual's Age. The first decision node specifies that if the Age is exactly 18, it is split into two segments based on their weight. If the weight of the person is less than 60, the classification is mentioned in the template, and if the weight is more than 60, we assume that there is a High Risk of getting a heart-related problem. We have then classified this decision tree further based on their age and smoking habits.
Such branches demonstrate the hierarchical decision-making process of the Sklearn Decision Tree that is commonly used for segmentation and classifications. These Sklearn Decision Tree templates are available in EdrawMind and can easily be downloaded to customize.
Conclusion
Sklearn Decision Tree is a powerful tool for machine learning in the Python programming language. As we saw in this detailed article, Scikit-learn's implementation helps the developers to communicate complex decision-making processes. In short, the Sklearn decision tree is an important tool that handles missing data and supports ensemble methods. If you are planning to make such comprehensive diagrams, you can always use EdrawMind. The tool is considered the best choice for making decision trees and you will find several connecting options that would help you create different nodes and leaf samples.
FAQ
-
How does a Decision Tree work in scikit-learn?
A decision tree in Scikit-Learn repeatedly splits data based on the features. It primarily aims to create a hierarchy of decisions for regression tasks that provides effective modeling. -
What are the key parameters of the DecisionTreeClassifier in scikit-learn?
Some of the key parameters of the DecisionTreeClassifier in Scikit-Learn include max depth, gini, entropy, minimum samples split, and leaf samples. -
What are some real-world applications of scikit-learn Decision Trees?
The real-world applications of the Scikit-Learn decision tree include scenarios from the healthcare industry where we are using it to predict some disease or using it in marketing to create customer segmentation.
